
티스토리 뷰

어떤 CPU를 위하여 정의되어 있는 명령어들의 집합
명령어 세트 설계를 위해 결정되어야 할 사항들
연산 종류 : CPU가 수행할 연산들의 수와 종류 및 복잡도
데이터 형태 : 연산을 수행할 데이터들의 형태, 데이터의 길이(비트 수), 수의 표현 방식 등
명령어 형식 : 명령어의 길이, 오퍼랜드 필드들의 수와 길이, 등
주소지정 방식 : 오퍼랜드의 주소를
연산의 종류
데이터 전송 : 레지스터와 레지스터 간, 레지스터와 기억장치 간, 혹은 기억장치와 기억장치 간에 데이터를 이동하는 동작
산술 연산 : 덧셈, 뺄셈, 곱셈 및 나눗셈과 같은 기본적인 산술 연산들
논리 연산 : 데이터의 각 비트들 간에 대한 AND, OR, NOT 및 exclusive-OR 연산
입출력(I/O) : CPU와 외부 장치들 간의 데이터 이동을 위한 동작들
프로그램 제어
명령어 실행 순서를 변경하는 연산들
분기(branch), 서브루틴 호출(subroutine call)
서브루틴 호출을 위한 명령어들
호출 명령어 (CALL 명령어)
현재의 PC 내용을 스택에 저장하고 서브루틴의 시작 주소로 분기하는 명령어
복귀 명령어 (RET 명령어)
CPU가 원래 실행하던 프로그램으로 되돌아가도록 하는 명령어
서브루틴들이 포함된 프로그램의 실행 과정
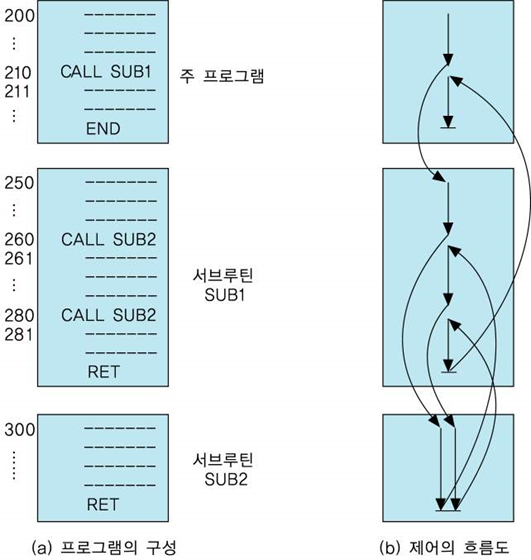
CALL/RET 명령어의 마이크로 연산
CALL X 명령어에 대한 마이크로-연산:
t0 : MBR PC
t1 : MAR SP, PC X
t2 : M[MAR] MBR, SP SP - 1
현재의 PC 내용(서브루틴 수행 완료 후에 복귀할 주소)을 SP가 지정하는 스택의 최상위(top of stack)에 저장
만약 주소지정 단위가 바이트이고 저장될 주소는 16비트라면, SP SP - 2
RET 명령어의 마이크로-연산
t0 : SP SP + 1
t1 : MAR SP
t2 : PC M[MAR]
서브루틴 수행 과정에서 스택의 변화

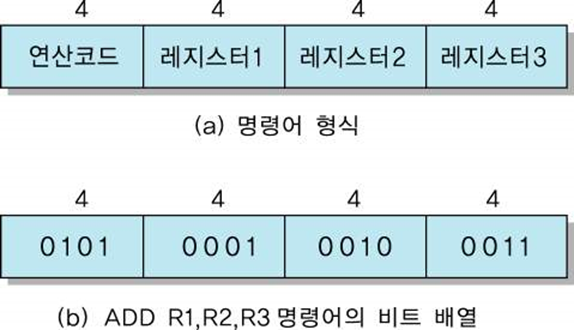
명령어 형식
명령어의 구성요소들
연산 코드(Operation Code)
수행될 연산을 지정(예: LOAD, ADD 등)
오퍼랜드(Operand)
연산을 수행하는 데 필요한 데이터 혹은 데이터의 주소
각 연산은 한개 혹은 두개의 입력 오퍼랜드들과 한개의 결과 오퍼랜드를 포함
데이터는 CPU 레지스터, 주기억장치, 혹은 I/O 장치에 위치
다음 명령어 주소(Next Instruction Address)
현재의 명령어 실행이 완료된 후에 다음 명령어를 인출할 위치 지정
분기 혹은 호출 명령어와 같이 실행 순서를 변경하는 경우에 필요
명령어 형식 (instruction format)
필드(field) : 명령어의 각 구성 요소들에 소요되는 비트들의 그룹
명령어 형식(instruction format) : 명령어 내 필드들의 수와 배치 방식 및 각 필드의 비트 수
명령어의 길이 = 단어 길이
명령어 형식의 예 : 세 개의 필드들로 구성된 16-비트 명령어

명령어 형식의 결정에서 고려할 사항들
연산 코드 필드 = 4 비트 24 = 16 가지의 연산들 정의 가능
만약 연산 코드 필드가 5 비트로 늘어나면, 25 = 32 가지 연산들 정의 가능
다른 필드의 길이가 감소
오퍼랜드 필드의 범위는 오퍼랜드의 종류에 따라 결정
데이터 : 표현 가능한 수의 크기가 결정
기억장치 주소 : CPU가 오퍼랜드 인출을 위하여 직접 주소를 지정할 수 있는 기억장치 영역의 범위가 결정
레지스터 번호 : 데이터 저장에 사용될 수 있는 레지스터의 수가 결정
오퍼랜드 필드의 범위 예
오퍼랜드1은 레지스터 번호를 지정하고, 오퍼랜드2는 기억장치 주소를 지정하는 경우
오퍼랜드1 = 4 비트 16 개의 레지스터 사용 가능
오퍼랜드2 = 8 비트 기억장치의 주소 범위 : 0 번지 ∼ 255 번지
위에서 두 오퍼랜드들을 하나로 통합하여 사용하는 경우
오퍼랜드가 2의 보수로 표현되는 데이터라면,표현 범위 : - 2048 ∼ + 2047
오퍼랜드가 기억장치 주소라면,212 = 4096 개의 기억장치 주소 지정 가능
오퍼랜드의 수에 따른 명령어 분류
1-주소 명령어(1-address instruction) : 오퍼랜드를 한 개만 포함하는 명령어
[예] ADD X ; AC AC + M[X]
2-주소 명령어(two-address instruction) : 두 개의 오퍼랜드를 포함하는 명령어.
[예] ADD R1, R2 ; R1 R1 + R2
MOV R1, R2 ; R1 R2
ADD R1, X ; R1 R1 + M[X]
3-주소 명령어(three-address instruction) : 세 개의 오퍼랜드들을 포함하는 명령어.
[예] ADD R1, R2, R3 ; R1 R2 + R3
1-주소 명령어의 예
길이가 16 비트인 1-주소 명령어에서 연산 코드가 5 비트일 때의 명령어 형식을 정의하고, 주소지정 가능한 기억장치 용량을 결정하라
주소지정 가능한 기억장치 용량 : 211 = 2048 바이트
명령어 형식

2-주소 명령어의 예
2-주소 명령어 형식을 사용하는 16-비트 CPU에서 연산 코드가 4 비트이고, 레지스터의 수는 16 개이다. (a) 두 오퍼랜드들이 모두 레지스터 번호인 경우와, (b) 한 오퍼랜드는 기억장치 주소인 경우의 명령어 형식을 정의하라

3-주소 명령어 형식의 예
명령어 형식이 프로그래밍에 미치는 영향 (예)
X = (A + B) x (C - D)
프로그래밍에 다음과 같은 니모닉을 가진 명령어들을 사용
ADD : 덧셈
SUB : 뺄셈
MUL : 곱셈
DIV : 나눗셈
MOV : 데이터 이동
LOAD : 기억장치로부터 데이터 적재
STOR : 기억장치로 데이터 저장
1-주소 명령어를 사용한 프로그램
LOAD A ; AC M[A]
ADD B ; AC AC + M[B]
STOR T ; M[T] AC
LOAD C ; AC M[C]
SUB D ; AC AC - M[D]
MUL T ; AC AC × M[T]
STOR X ; M[X] ← AC
M[A]는 기억장치 A 번지의 내용, T는 기억장치 내의 임시 저장장소의 주소
프로그램의 길이 = 7
2-주소 명령어를 사용한 프로그램
MOV R1, A ; R1 M[A]
ADD R1, B ; R1 R1 + M[B]
MOV R2, C ; R2 M[C]
SUB R2, D ; R2 R2 - M[D]
MUL R1, R2 ; R1 R1 × R2
MOV X, R1 ; M[X] R1
프로그램의 길이 = 6
3-주소 명령어를 사용한 프로그램
ADD R1, A, B ; R1 M[A] + M[B]
SUB R2, C, D ; R2 M[C] - M[D]
MUL X, R1, R2 ; M[X] R1 × R2
프로그램의 길이 = 3
단점
명령어의 길이 증가한다
명령어 해독 과정이 복잡해진다
주소지정 방식
다양한 주소지정 방식(addressing mode)을 사용하는 이유 : 제한된 수의 명령어 비트들을 이용하여 사용자(혹은 프로그래머)로 하여금 여러 가지 방법으로 오퍼랜드를 지정하고 더 큰 용량의 기억장치를 사용할 수 있도록 하기 위함
기호
EA : 유효 주소(Effective Address), 즉 데이터가 저장된 기억장치의 실제 주소
A : 명령어 내의 주소 필드 내용 (오퍼랜드 필드가 기억장치 주소를 나타내는 경우)
R : 명령어 내의 레지스터 번호 (오퍼랜드 필드가 레지스터 번호를 나타내는 경우)
(A) : 기억장치 A 번지의 내용
(R) : 레지스터 R의 내용
주소지정 방식의 종류
직접 주소지정 방식 (direct addressing mode)
간접 주소지정 방식 (indirect addressing mode)
묵시적 주소지정 방식 (implied addressing mode)
즉치 주소지정 방식 (immediate addressing mode)
레지스터 주소지정 방식 (register addressing mode)
레지스터 간접 주소지정 방식 (register-indirect addressing mode)
변위 주소지정 방식 (displacement addressing mode)
상대 주소지정 방식(relative addressing mode)
인덱스 주소지정 방식(indexed addressing mode)
베이스-레지스터 주소지정 방식(base-register addressing mode)
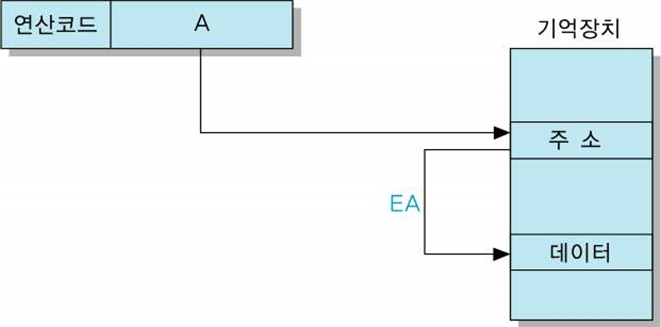
직접 주소지정 방식
오퍼랜드 필드의 내용이 유효 주소가 되는 방식
EA = A
[장점] 데이터 인출을 위하여 한 번의 기억장치 액세스만 필요
[단점] 연산 코드를 제외하고 남은 비트들만 주소 비트로 사용될 수 있기 때문에 직접 지정할 수 있는 기억장소의 수가 제한

간접 주소지정 방식
오퍼랜드 필드에 기억장치 주소가 저장되어 있지만, 그 주소가 가리키는 기억 장소에 데이터의 유효 주소가 저장되어 있도록 하는 방식
EA = (A)
[장점] 최대 기억장치용량이 단어의 길이에 의하여 결정 확장가능
단어 길이가 n 비트라면, 최대 2n 개의 기억 장소들을 주소지정 가능
[단점] 실행 사이클 동안에 두 번의 기억장치 액세스가 필요
첫 번째 액세스는 주소를 읽어 오기 위한 것
두 번째는 그 주소가 지정하는 위치로부터 실제 데이터를 인출하기 위한 것
명령어 형식에서 간접비트(I) 필요
만약 I = 0 이면, 직접 주소지정 방식
만약 I = 1 이면, 간접 주소지정 방식
다단계(multi-level) 간접 주소지정 방식
EA = ( ( . . (A) . . ) )

묵시적 주소지정 방식
명령어 실행에 필요한 데이터의 위치가 묵시적으로 지정되는 방식
‘SHL 명령어’ : 누산기의 내용을 좌측으로 쉬프트(shift)
‘PUSH R1 명령어’ : 레지스터 R1의 내용을 스택에 저장
[장점] 명령어 길이가 짧다
[단점] 종류가 제한된다
즉치 주소지정 방식
데이터가 명령어에 포함되어 있는 방식
오퍼랜드 필드의 내용이 연산에 사용할 실제 데이터
용도
프로그램에서 레지스터들이나 변수의 초기 값을 어떤 상수값(constant value)으로 세트하는 데 유용하게 사용
[장점] 데이터를 인출하기 위하여 기억장치를 액세스할 필요가 없음
[단점] 상수값의 크기가 오퍼랜드 필드의 비트 수에 의하여 제한

레지스터 주소지정 방식
연산에 사용할 데이터가 레지스터에 저장되어 있는 방식
EA = R
주소지정에 사용될 수 있는 레지스터들의 수 = 2k 개
(k는 오퍼랜드 비트 수)

레지스터 주소지정 방식
[장점]
오퍼랜드 필드의 비트 수가 적어도 된다
데이터 인출을 위하여 기억장치 액세스가 필요 없다
[단점]
데이터가 저장될 수 있는 공간이 CPU 내부 레지스터들로 제한
레지스터 간접 주소지정 방식
오퍼랜드 필드(레지스터 번호)가 가리키는 레지스터의 내용을 유효 주소로 사용하여 실제 데이터를 인출하는 방식
EA = (R)

레지스터 간접 주소지정 방식
[장점] 주소지정 할 수 있는 기억장치 영역이 확장
레지스터의 길이 = 16 비트라면, 주소지정 영역: 216 = 64K 바이트
레지스터의 길이 = 32 비트라면, 주소지정 영역: 232 = 4G 바이트
변위 주소지정 방식
직접 주소지정과 레지스터 간접 주소지정 방식의 조합
EA = A + (R)
명령어에 포함된 변위 A값과 R이 가리키는 레지스터의 내용을 더하여유효 주소를 결정
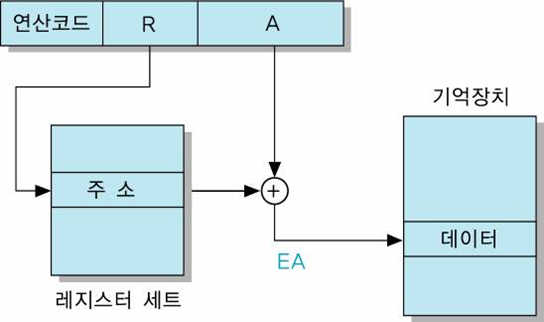
변위 주소지정 방식
사용되는 레지스터에 따라 여러 종류의 변위 주소지정 방식 정의
PC 상대 주소지정 방식(relative addressing mode)
인덱스 레지스터 인덱스 주소지정 방식(indexed addressing mode)
베이스 레지스터 베이스-레지스터 주소지정 방식(base-register addressing mode)
상대 주소지정 방식
프로그램 카운터(PC)를 레지스터로 사용. 주로 분기 명령어에서 사용
EA = A + (PC)
A는 2의 보수
A ≥ 0 : 앞(forward) 방향으로 분기
A < 0 : 뒷(backward) 방향으로 분기
[예] JUMP 명령어가 450 번지에 저장. 명령어 인출 후, PC 내용 = 451
만약 오퍼랜드 A = + 21 분기 목적지 주소 = 451 + 21 = 472 번지
만약 오퍼랜드 A = - 50 분기 목적지 주소 = 451 - 50 = 401 번지
[장점] 전체 기억장치 주소가 명령어에 포함되어야 하는 일반적인 분기 명령어보다 적은 수의 비트만 있으면 된다
[단점] 분기 범위가 오퍼랜드 필드의 길이에 의하여 제한
인덱스 주소지정 방식
인덱스 레지스터의 내용과 변위 A를 더하여 유효 주소를 결정
EA = (IX) + A
인덱스 레지스터(IX) : 인덱스(index) 값을 저장하는 특수 레지스터
[주요 용도] 배열 데이터 액세스
자동 인덱싱(autoindexing)
명령어가 실행될 때마다 인덱스 레지스터의 내용이 자동적으로 증가 혹은 감소
이 방식이 사용된 명령어가 실행되면 아래의 두 연산이 연속적으로 수행
EA = (IX) + A
IX IX + 1
인덱스 주소지정 방식의 예
데이터 배열이 기억장치의 500 번지부터 저장되어 있고, 명령어의 주소 필드에 500이 포함되어 있을 때, 인덱스 레지스터의 내용 (IX) = 3 이라면 데이터 배열의 4 번째 데이터 액세스

베이스-레지스터 주소지정 방식
베이스 레지스터의 내용과 변위 A를 더하여 유효 주소를 결정
EA = (BR) + A
[주요 용도] 서로 다른 세그먼트내 프로그램의 위치를 지정
PDP 계열 프로세서의 명령어 형식
PDP-10 프로세서 : 고정 길이의 명령어 형식 사용
단어의 길이 = 36 비트, 명령어의 길이 = 36 비트
연산 코드 = 9 비트 최대 512 종류의 연산 허용 (실제 365 개)

PDP-11 프로세서 : 다양한 길이의 명령어 형식들 사용
연산 코드 = 4 ∼ 16 비트
주소 개수 : 0, 1, 2 개
PDP-11의 명령어 형식

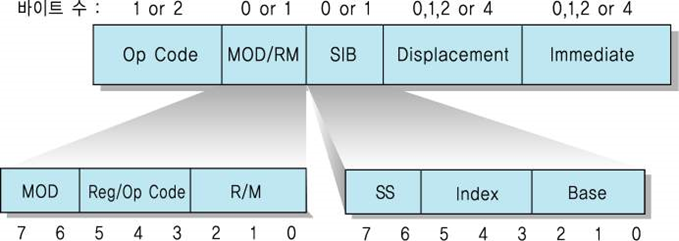
펜티엄 프로세서의 명령어 형식
선형 주소(linear address: LA)
유효 주소 + 세그먼트의 시작 주소
세그먼트의 시작 주소는 세그먼트 레지스터에 저장
| 주소지정 방식 | 유효 주소(EA) | 선형 주소(LA) |
| 즉치 방식 레지스터 방식 변위 방식 베이스 방식 변위를 가진 베이스 방식 변위를 가진 인덱스 방식 인덱스와 변위를 가진 베이스 방식 상대 방식 |
데이터 = A EA = R EA = A EA = (BR) EA = (BR)+A EA = (IX)+A EA = (IX)+(BR)+A EA = (PC)+A |
LA = R LA = (SR)+EA LA = (SR)+EA LA = (SR)+EA LA = (SR)+EA LA = (SR)+EA LA = EA |
펜티엄 프로세서의 명령어 형식
즉치 방식(immediate mode) : 데이터가 명령어에 포함되어 있는 방식
데이터의 길이 = 바이트, 단어(word) 혹은 2중 단어(double word)
레지스터 방식(register mode) : 유효 주소가 레지스터에 들어 있는 방식
변위 방식(displacement mode) : 명령어에 포함된 변위값과 세그먼트 레지스터 SR의 내용을 더하여 선형주소 LA를 생성하는 방식
베이스 방식(base mode) : 레지스터 간접 주소지정에 해당
상대 방식(relative mode) : 변위값과 프로그램 카운터의 값을 더하여 다음 명령어의 주소로 사용하는 방식
펜티엄 명령어 형식의 필드들
연산 코드(Op code) : 연산의 종류 지정. 길이 = 1 혹은 2 바이트
MOD/RM : 주소지정 방식 지정
SIB : MOD/RM 필드와 결합하여 주소지정 방식을 완성
변위(displacement) : 부호화된 정수(변위)를 저장
즉치(immediate) : 즉치 데이터를 저장
'It' 카테고리의 다른 글
| 네트워크 기초 용어 (0) | 2022.08.17 |
|---|---|
| 리눅스의 특징 (0) | 2022.08.17 |
| 명령어 파이프라이닝 (0) | 2022.08.16 |
| 명령어 실행 (0) | 2022.08.16 |
| Spring AOP 4-1 AOP (0) | 2022.08.15 |

- Total
- Today
- Yesterday
- 하나님의 마음 정식자막
- 영화
- 한국영화
- 러브 라이프 다운로드
- 영화순위
- 러브 라이프 정식자막
- 오늘의사건
- 하나님의 마음 다운로드
- 하나님의 마음 한글자막
- 영화추천
- 러브 라이프 한글자막
- 오늘의이슈
- 하나님의 마음 고화질
- 옛날영화
- 러브 라이프 무료보기
- 박스오피스
- 실검
- 하나님의 마음 마그넷
- 러브 라이프 예고편
- 하나님의 마음 바로보기
- 하나님의 마음 다시보기
- 러브 라이프 토렌트
- 추천영화
- 하나님의 마음 예고편
- 실시간검색어
- 외국영화
- 하나님의 마음 무료보기
- 영화소개
- Movie
- 하나님의 마음 토렌트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |